The smallest Git commit
I was wondering: Just how small can a Git repository be?
Making a small Git repository by hand
Is an empty directory already a Git repository according to Git?
$ mkdir smallgit
$ cd smallgit
$ git status
fatal: not a git repository (or any of the parent directories): .git
Okay, apparently not. How about creating an empty .git directory and try again?
$ mkdir .git
$ git status
fatal: not a git repository (or any of the parent directories): .git
Still no luck. Let's have a look at what Git wants to read.
$ strace git status
[...]
close(3) = 0
getcwd("/home/laria/smallgit", 129) = 21
stat("/home/laria/smallgit", {st_mode=S_IFDIR|0755, st_size=4096, ...}) = 0
stat("/home/laria/smallgit/.git", {st_mode=S_IFDIR|0755, st_size=4096, ...}) = 0
lstat("/home/laria/smallgit/.git/HEAD", 0x7ffde3810df0) = -1 ENOENT (No such file or directory)
It seems like Git is missing the .git/HEAD file. This is the file that tracks the current head / currently checked out branch. Can we get away with an empty one?
$ touch .git/HEAD
$ git status
fatal: not a git repository (or any of the parent directories): .git
Hmm, still no luck. Perhaps we need to have ./git/HEAD point to a branch? So what is in this file anyway? Git's excellent documentation to the rescue: gitrepository-layout(5) (You can also access this using git help repository-layout).
HEADA symref (see glossary) to the
refs/heads/namespace describing the currently active branch. [...] [A] valid Git repository must have the HEAD file.
Alright, and what is a symref? To quote the mentioned glossary:
Symbolic reference: instead of containing the SHA-1 id itself, it is of the format ref: refs/some/thing and when referenced, it recursively dereferences to this reference.
So, we only have to put in a reference to a branch in here?
$ echo "ref: refs/heads/main" > .git/HEAD
$ git status
fatal: not a git repository (or any of the parent directories): .git
Still nothing? After some more strace action, I found out that Git also needs the directories .git/objects and .git/refs.
$ mkdir .git/objects
$ mkdir .git/refs
$ git status
On branch main
No commits yet
nothing to commit (create/copy files and use "git add" to track)
Hooray! We made a Git repository by hand!
We can make it a bit smaller yet, by having a shorter symref in the HEAD file, after all main is just the default name for the initial branch. Also, you apparently don't need the space after ref:".
$ echo "ref:refs/heads/x" > .git/HEAD
$ git status
On branch x
No commits yet
nothing to commit (create/copy files and use "git add" to track)
To summarize, here's what we have done so far:
$ mkdir smallgit
$ cd smallgit
$ mkdir .git
$ mkdir .git/objects
$ mkdir .git/refs
$ echo "ref:refs/heads/x" > .git/HEAD
$ git status
On branch x
No commits yet
nothing to commit (create/copy files and use "git add" to track)
So I guess this answers my original question. But a repository with no commits is a bit boring, so what about the smallest Git commit?
The smallest Git commit
Let's be a bit more precise here and first define what we want to happen.
- We want our branch
xfrom above to have a commit. - We want
git statusto show the commit successfully. - We want
git logto show the commit successfully. - We want the smallest amount of uncompressed bytes for all objects of the commit. I'll explain how commits are stored later in the article.
Let's first explore how a commit is stored in Git's database.
How Git stores commits
Perhaps you've already heard that Git stores everything as objects in a content-addressable storage. But what does that mean?
To explore this, let's create a new repository with a commit in it and play around with it:
$ mkdir testgit
$ cd testgit
$ git init
$ echo 'Hello World!' > README
$ git add README
$ git commit -m 'Initial commit'
[main (root-commit) 8480a0b] Initial commit
1 file changed, 1 insertion(+)
create mode 100644 README
$ git show
commit 8480a0b5a4f8e19bee89d103d977b7208e6dd3c2 (HEAD -> main)
Author: test <test@example.com>
Date: Sat Jan 2 13:04:53 2021 +0100
Initial commit
diff --git a/README b/README
new file mode 100644
index 0000000..980a0d5
--- /dev/null
+++ b/README
@@ -0,0 +1 @@
+Hello World!
So we've got a repository with one commit "Initial commit" that contains one "README" file with the content "Hello World!". The git show command shows us the newly created commit and tells us that it has the commit name 8480a0b5a4f8e19bee89d103d977b7208e6dd3c2 (If you play along at home, you'll have a different name here).
That name looks an awful lot like a hash. In fact, it is a hash. It's the SHA-1 hash of the commit object. Git stores it's objects under .git/objects/XX/XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX, where the Xs are the digits of the hash. The objects are stored compressed (using the deflate algorithm).
(Objects can also be stored in pack files found under .git/objects/pack, but we'll ignore that for the rest of the article)
We can verify the hash by using zlib-flate -uncompress to uncompress the data and sha1sum - to calculate the hash:
$ zlib-flate -uncompress < .git/objects/84/80a0b5a4f8e19bee89d103d977b7208e6dd3c2 | sha1sum -
8480a0b5a4f8e19bee89d103d977b7208e6dd3c2 -
Neat!
This, by the way, is where the content-addressability comes into play: the name of the object can be derived by it's content (by calculating the SHA-1 hash). Therefore, if you save an object twice, it will actually be saved only once, as it will get the same name, as it has the same content, both times. This has two big advantages:
- You get content deduplication for free, as only one copy of the content will be saved.
- The integrity of an object can be easily checked: Just calculate the SHA-1 hash and compare it with it's name.
Now let's take a look at what's in the commit object:
$ zlib-flate -uncompress < .git/objects/84/80a0b5a4f8e19bee89d103d977b7208e6dd3c2 | less -F
commit 161^@tree b4eecafa9be2f2006ce1b709d6857b07069b4608
author test <test@example.com> 1609589093 +0100
committer test <test@example.com> 1609589093 +0100
Initial commit
It starts with commit 161^@: commit is the object type, 161 is the size of the object payload, and ^@ is less' way of displaying a zero-byte that is used to separate the object header <type> <size> from the payload.
We can see the commit message itself, the author and committer names and dates (they are the same here, but they can be different, for example when you turn a patch into a commit using git am or when rebasing). There also is a line that starts with tree, which points to the content of the commit. Let's see what's inside that:
tree 34^@100644 README^@<98>
^M_^Y<A6>KK0<A8>}B^F<AA><DE>Xrk`<E3>
Oof. Apparently we've got some binary data here. You can make out the name of our README file, but that's about it. But we can also use some of Git's own tools to view this object:
$ git cat-file -p b4eecafa9be2f2006ce1b709d6857b07069b4608
100644 blob 980a0d5f19a64b4b30a87d4206aade58726b60e3 README
Ah, much better! If we now follow the object name of the README entry, we'll get the content of README:
$ zlib-flate -uncompress < .git/objects/98/0a0d5f19a64b4b30a87d4206aade58726b60e3 | less -F
blob 13^@Hello World!
or
$ git cat-file -p 980a0d5f19a64b4b30a87d4206aade58726b60e3
Hello World!
Now that we have some idea of what's going on, let's actually try and construct a commit object from scratch!
Manually building a commit
Above we've seen that Git stores commits as deflate-compressed objects with a name derived from their SHA-1 hash and that an object always starts with the object type and the size of the payload (encoded as an ASCII decimal number). So let's hack together a small helper function to write objects:
# Write a Git object. Needs the object type as it's first argument and # accepts the object content on stdin. write_git_object() { # Store the type argument type="$1" # Create some temporary files tmp_payload="$(mktemp)" tmp_object="$(mktemp)" # Write the payload to a temporary file and calculate it's size payload_size="$(tee "$tmp_payload" | wc -c)" # Write the uncompressed object to a temporary file { printf '%s %d\0' "$type" "$payload_size" # Header cat "$tmp_payload" # Payload } > "$tmp_object" # Calculate the object hash hash="$(sha1sum - < "$tmp_object" | sed 's/\s.*$//')" # Split the commit hash into the first 2 digits and the remainder hash_head="$(echo "$hash" | sed 's/^\(..\).*$/\1/')" hash_tail="$(echo "$hash" | sed 's/^..\(.*\)$/\1/')" # Create the directory, if it doesn't exist dir=".git/objects/$hash_head" [ -d "$dir" ] || mkdir -p "$dir" # Write the compressed object into it's proper place in the objects dir zlib-flate -compress < "$tmp_object" > "$dir/$hash_tail" # Echo the hash and the uncompressed object size echo "hash: $hash" echo "size: $(wc -c < "$tmp_object")" # Tidy up the temporary files rm -f "$tmp_payload" rm -f "$tmp_object" }
(Note: You can also use git hash-object to create the objects, but this contraption above let's us see what's going on)
Perhaps a completely empty commit object will do the trick?
$ write_git_object commit </dev/null
hash: dcf5b16e76cce7425d0beaef62d79a7d10fce1f5
size: 9
$ git show dcf5b16e76cce7425d0beaef62d79a7d10fce1f5
error: bogus commit object dcf5b16e76cce7425d0beaef62d79a7d10fce1f5
fatal: bad object dcf5b16e76cce7425d0beaef62d79a7d10fce1f5
Okay, that didn't work. "bogus commit", what does that even mean? Thankfully, Git is open source, so we can take a look to find out.
I cloned the official Git repository (at the time of writing, v2.30.0 was the current version, which corresponds to the commit 71ca53e8125e36e) and did a global search for "bogus commit". I found this place in the function parse_commit_buffer in file commit.c:
if (tail <= bufptr + tree_entry_len + 1 || memcmp(bufptr, "tree ", 5) || bufptr[tree_entry_len] != '\n') return error("bogus commit object %s", oid_to_hex(&item->object.oid));
So it looks like we need to at least have a tree entry in the commit object, and if we read a bit more of the source, it seems like it must be a valid tree that Git knows about:
if (get_oid_hex(bufptr + 5, &parent) < 0) return error("bad tree pointer in commit %s", oid_to_hex(&item->object.oid)); tree = lookup_tree(r, &parent); if (!tree) return error("bad tree pointer %s in commit %s", oid_to_hex(&parent), oid_to_hex(&item->object.oid)); set_commit_tree(item, tree);
Okay, so let's try to create an empty tree and create a commit with that tree:
$ write_git_object tree </dev/null
hash: 4b825dc642cb6eb9a060e54bf8d69288fbee4904
size: 7
$ printf 'tree 4b825dc642cb6eb9a060e54bf8d69288fbee4904\n' | write_git_object commit
hash: e43fc45fe9861f11199bfc430939749be99df922
size: 56
$ git show e43fc45fe9861f11199bfc430939749be99df922
error: bogus commit object e43fc45fe9861f11199bfc430939749be99df922
fatal: bad object e43fc45fe9861f11199bfc430939749be99df922
Huh, still bogus commit? I didn't find another place in Git's source with "bogus commit" that looks like something of relevance. So I went back and read the source a bit more carefully. Of interest is till this if statement:
if (tail <= bufptr + tree_entry_len + 1 || memcmp(bufptr, "tree ", 5) || bufptr[tree_entry_len] != '\n') return error("bogus commit object %s", oid_to_hex(&item->object.oid));
tail is essentially the end of the buffer where the object is stored in memory (that's the buffer bufptr points to at the time). tree_entry_len is set to the_hash_algo->hexsz + 5 in that function. I assume the_hash_algo->hexsz here means the length of the hex encoded hash and 5 is likely added for the length of "tree ". So, tail <= bufptr + tree_entry_len + 1 boils down to size <= the_hash_algo->hexsz + 5 + 1. The size of our objects payload is 46 bytes and the length of a hex encoded SHA-1 hash is 40 bytes, so we get 46 <= 40 + 5 + 1, so our object satisfies that condition and Git will bail out.
So, what about adding another newline character?
$ printf 'tree 4b825dc642cb6eb9a060e54bf8d69288fbee4904\n\n' | write_git_object commit
hash: 8d7ff291d28b7f1109200d31f87a6f98fe7df90e
size: 57
$ git show 8d7ff291d28b7f1109200d31f87a6f98fe7df90e
commit 8d7ff291d28b7f1109200d31f87a6f98fe7df90e
Bingo! Looks like git status accepts this commit! What about git log?
$ git log 8d7ff291d28b7f1109200d31f87a6f98fe7df90e
commit 8d7ff291d28b7f1109200d31f87a6f98fe7df90e
Looks good too! Now all we have to do is set the branch to that commit.
$ mkdir .git/refs/heads
$ echo 8d7ff291d28b7f1109200d31f87a6f98fe7df90e > .git/refs/heads/x
$ git show
commit 8d7ff291d28b7f1109200d31f87a6f98fe7df90e (HEAD -> x)
$ git log
commit 8d7ff291d28b7f1109200d31f87a6f98fe7df90e (HEAD -> x)
And we're done! We now have a .git directory with 4 files in 5 directories and the objects have an uncompressed total size of 7 + 57 = 64 bytes (after having deleted the objects that didn't work out).
$ tree .git
.git
|-- HEAD
|-- objects
| |-- 4b
| | '-- 825dc642cb6eb9a060e54bf8d69288fbee4904
| |-- 8d
| '-- 7ff291d28b7f1109200d31f87a6f98fe7df90e
'-- refs
'-- heads
'-- x
5 directories, 4 files
And here is a script that summarizes this all and create such an repository in the current directory (Note that the write_git_object function was slightly modified to only output the hash):
#!/bin/sh # Write a Git object. Needs the object type as it's first argument and # accepts the object content on stdin. write_git_object() { # Store the type argument type="$1" # Create some temporary files tmp_payload="$(mktemp)" tmp_object="$(mktemp)" # Write the payload to a temporary file and calculate it's size payload_size="$(tee "$tmp_payload" | wc -c)" # Write the uncompressed object to a temporary file { printf '%s %d\0' "$type" "$payload_size" # Header cat "$tmp_payload" # Payload } > "$tmp_object" # Calculate the object hash hash="$(sha1sum - < "$tmp_object" | sed 's/\s.*$//')" # Split the commit hash into the first 2 digits and the remainder hash_head="$(echo "$hash" | sed 's/^\(..\).*$/\1/')" hash_tail="$(echo "$hash" | sed 's/^..\(.*\)$/\1/')" # Create the directory, if it doesn't exist dir=".git/objects/$hash_head" [ -d "$dir" ] || mkdir -p "$dir" # Write the compressed object into it's proper place in the objects dir zlib-flate -compress < "$tmp_object" > "$dir/$hash_tail" # Echo the hash and the uncompressed object size echo "$hash" # Tidy up the temporary files rm -f "$tmp_payload" rm -f "$tmp_object" } # Create .git directory with necessary directories mkdir .git mkdir -p .git/objects .git/refs/heads # Create tree and commit object treehash="$(write_git_object tree </dev/null)" commithash="$(printf 'tree %s\n\n' "$treehash" | write_git_object commit)" # Create branch x, pointing to the commit echo "$commithash" > .git/refs/heads/x # Make x the current branch echo "ref:refs/heads/x" > .git/HEAD
How do other tools handle this repo?
Rather poorly. While gitk was able to successfully open the repository, I was not able to push to a GitHub repository:
$ git push -u origin x
Enumerating objects: 2, done.
Counting objects: 100% (2/2), done.
Writing objects: 100% (2/2), 97 bytes | 97.00 KiB/s, done.
Total 2 (delta 0), reused 0 (delta 0), pack-reused 0
remote: error: object 8d7ff291d28b7f1109200d31f87a6f98fe7df90e: missingAuthor: invalid format - expected 'author' line
remote: fatal: fsck error in packed object
error: remote unpack failed: index-pack abnormal exit
To github.com:silvasur/smallgit.git
! [remote rejected] x -> x (failed)
error: failed to push some refs to 'github.com:silvasur/smallgit.git'
Sublime Merge also didn't like the repository, aborting with an error message:
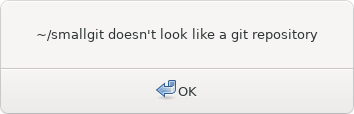
And in fact even git fsck says something is broken:
$ git fsck
error in commit 8d7ff291d28b7f1109200d31f87a6f98fe7df90e: missingAuthor: invalid format - expected 'author' line
Checking object directories: 100% (256/256), done.
Perhaps another thing to try is to construct something git fsck is happy with. But this is enough for now, perhaps I'll continue this later.